

Author: Asa Letourneau
Online Engagement Officer
Using Transkribus
With over 100 shelf kilometres of historic Victorian government archives, to both digitise and transcribe, from eye-bending cursive to readable text, Public Record Office Victoria has relied on volunteers to diligently perform these tasks so family and history research can be made possible online. While typeface has been relatively easy to transcribe by automation tools (e.g. Trove) handwriting has been more difficult to auto-transcribe with any accuracy.
With the growth in artificial intelligence and machine learning of 19th century cursive hand-writing patterns, we are now exploring additional ways of dealing with this age-old challenge. Simply put, machine learning is a way to teach a computer with some special software how to perform a given task by ‘training and correcting’ it along the way.
Experiment one: single hand transcription
In 2023 we took our first steps using a Machine Learning tool called Transkribus to explore the extent to which we could automatically train it to transcribe a variety of handwritten records in our custody. We started by training it on a series of correspondence letters written by mostly one hand. It took about 70 pages to return an 'character' error rate of less that 10% and it proved effective; namely the model, when applied against a larger set of over 100 pages, transcribed them with equal accuracy.
But, it took a month or so to produce the model LLM (Large Language Model) and we determined that while this approach is good for private collections whom preserve people's diaries or at a public library with bequeathed collections, it may not be ideal for a government archive where the records are written by many hands, if not hundreds of hands. The time invested in the model, however, was off-set by the pace of transcription.
Result: It took over a month to train the model, 11 minutes for the private model to transcribe 23 records with a CER (character error rate) of 5%. In short, roughly a day to transcribe 1000 pages.
Experiment two: Use of Transkribus’ public model to transcribe Ned Kelly police correspondence
Following the success of a private model, this step experimented with a public model available to Transkribus license holders. The model is called Super Model Text Titan 1, trained over millions of publicly shared handwritten records. The public model was applied against all of the digitised records from the Ned Kelly police correspondence files and within our account we can even search across the transcribed data for specific terms. The benefit of this scale of transcription cannot be underestimated. 6,700 records transcribed across 5 series.

Result: It took 28 seconds to transcribe one page and roughly one week to transcribe the entire collection, with a character error rate of around 5%.
Unfortunately the upload process didn't match our expectations and we had to transfer thousands of pages via cloud transfer to the team in Europe to ingest for us. Fortunately, Transkribus adhere to strict European security standards for their data storage and all of the records are on open access and available to view on our catalogue, un-transcribed. We are about to begin a pilot review process with volunteers to determine the estimated pace of correction for the transcribed data, along with a broader conversation internally for our tolerance of error rate.
With more work we hope one day researchers will no longer be confronted by the challenge of reading cursive and we can automate transcription at the digitisation workflow. The other great benefit of course is that by turning digitised handwritten records into searchable text we suddenly make the archives much more discoverable.
Searchable text within Transkribus
Imagine wanting to find all records from VPRS 4965 Kelly Historical Collection - Part 1 Police Branch containing a reference to the township of Glenrowan, famous for hosting the final siege and capture of the Kelly Gang in 1880. It’s comforting to know that with the help of Machine Leaning in the future, this may be an easy task to achieve. The screenshot below depicts results from performing such a search across the thousands of records we have already transcribed from VPRS 4965 using Machine Learning. You’ll notice two things here, firstly the digitised record with the handwritten word ‘Glenrowan’ recognised by the machine, then the transcription it creates as searchable text. As you’ll see below, the beauty of course is that the text is found throughout the handwriting of many authors.

Turning tabular record data into Excel spreadsheets
Now that we are becoming more comfortable using machine learning for transcribing records, we are already looking to a broader application of the tool for indexes and registers.
Like many archival systems researchers quite often have to conduct multi-step searching. First, they must look in an index for a name or file number, and then apply that file number against a different set of archives to retrieve the file of documents. This is typical for family history research or research about property, or any number of correspondence files. In fact, it's pretty typical of historic collections.
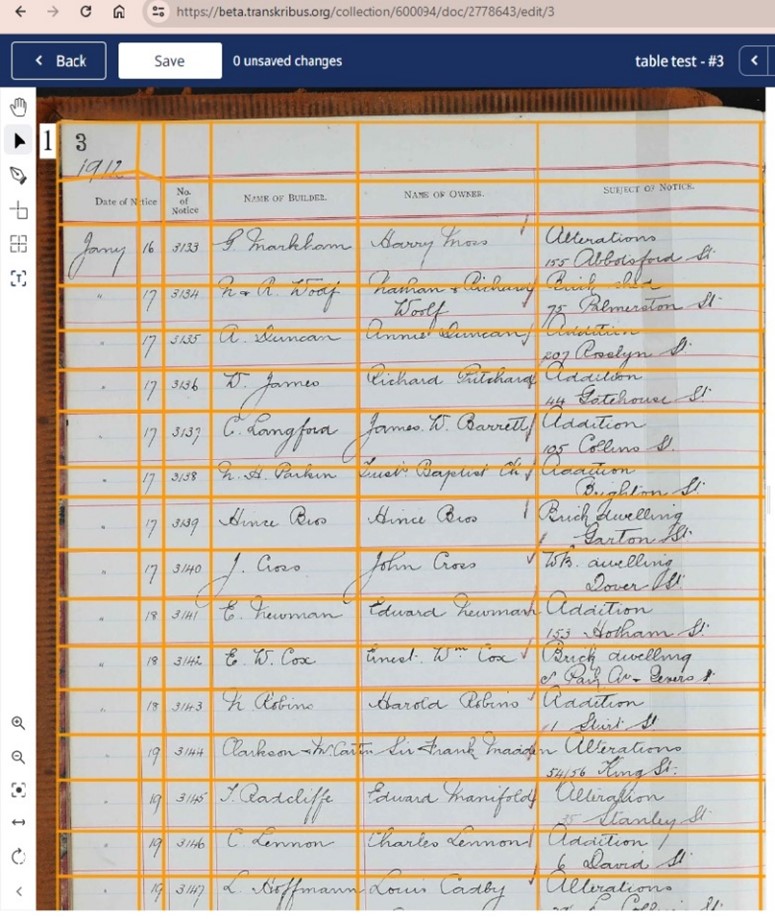
For this experiment we combined machine learning to teach it to copy the pattern of the tabular grid across the whole historic volume, and then applied the public transcription model to auto-transcribe the cursive writing on the page.
This is typical for a series like VPRS 9289 Building Notices Register and Index: records which contain historic building requests and the architect's name. These series are predominantly made up of volumes containing hundreds of pages of tabular data that in the past would have been painstakingly transcribed by volunteers to ‘free’ up the data from the columns and rows they were written in and make the data searchable.
Below you will see how Transkribus allows us to define the columns and rows of a typical tabular volume by ‘training’ it to recognize similar records into the future. Once this is done, we can then use Transkribus to transcribe the tabular data and export the results to Excel in a matter of hours as opposed to weeks.
Experiment: Transkribus was ‘trained’ on 30 pages of tabular data to specifically identify the grid shape, and to ensure consistency in the table, with the correct rows and columns on each page. It was then applied against series 9289, a series called Public Notices of Intention to Build. The digitised pages were then transcribed with the available public model and enjoyed similar results, a character error rate of roughly 5%.
To infinity and beyond!
You’ll be happy to know that we are not resting on our laurels just yet.
Alongside automatic transcription, we are also exploring automatic image caption technology as just one more service to make the state archives more accessible and the entire research experience more enjoyable.
Fore more information about this pilot please contact project manager Asa Letourneau by emailing him via media@prov.vic.gov.au
Material in the Public Record Office Victoria archival collection contains words and descriptions that reflect attitudes and government policies at different times which may be insensitive and upsetting
Aboriginal and Torres Strait Islander Peoples should be aware the collection and website may contain images, voices and names of deceased persons.
PROV provides advice to researchers wishing to access, publish or re-use records about Aboriginal Peoples